-
[공모전] 개인 정보 및 유해 이미지 모자이크 처리 시스템Project 2021. 2. 24. 17:50728x90
0. 순서
-
서비스 소개
-
시스템 구성 및 구현
-
테스트 및 시연 영상
-
예제 소스코드 설명
** 원본 발표자료의 내용을 요약하여 작성하였습니다.
1. 서비스 소개
1) YoMo ?
- YoMo = You only Mosaic once
- YOLO* 알고리즘을 활용한 유해물 및 개인정보 탐지 및 처리 서비스
- YOLO (You Only Look Once) : 이미지를 여러 그리드로 나누어 Boundary box 생성, 특징 추출, 클래스 분류를 동시에 진행하는 객체탐지 알고리즘으로, 구조가 비교적 간단하고 처리 속도가 매우 빠르다는 장점이 있다.
2) 주요 기능
- 동영상 속 유해 이미지(칼, 담배 등) 및 개인정보 이미지(차 번호판, 도로명 주소판 등)를 탐지하여 모자이크 처리

3) 필요성
- 생략
4) 기대 효과
(1) 불특정 다수의 미디어 이용자에게 유해 이미지 및 개인정보 이미지 유출을 사전에 차단할 수 있다.
(2) 동영상 편집자에게 편집 전 하나의 전처리 기능으로써 반복 작업을 없애, 피로감을 낮춰줄 수 있다.

2. 시스템 구성 및 구현
1) 시스템 구성도

2) 시스템 구현
(1) 웹 (Web)
- YoMo 웹 어플리케이션 : 사용자가 별도의 프로그램을 설치하지 않아도 서비스를 이용할 수 있도록 웹 사이트를 제작
- 구성 요소 : Cloud service, Nginx (웹 서버), Node.js (자바스크립트 런타임), 브라우저
- 사용 언어 : JavaScript, CSS, HTML

- 동작 과정 (기능 별)

동영상 업로드 
모자이크 처리 
동영상 다운로드 (2) 탐지 (Detect)
- 이미지 데이터 수집 : 기존 방식은 웹 크롤링을 통한 “이미지 수집”만을 이용하여 이미지의 중복, 낮은 품질의 이미지 등으로 인한 문제 발생 때문에, 이미지 개수는 많지만 학습에 유용하지 않음. 따라서 현재 방식으로 크롤링 이미지 수집 + 직접 이미지 촬영 수집 이미지중 중복, 낮은 품질의 이미지 제거로 변경
- 이미지 데이터 변환 : 이미지 데이터를 효율적으로 늘리기 위한 과정 (대칭이동, 밝기조절)
- 총 데이터 개수 : 담배 : 4129장, 칼 : 2396장, 차번호판 : 2252장, 도로명주소판 : 1670장
- 이미지 라벨링 : 수집한 이미지에서 탐지해야 할 영역을 지정, 라벨링 도구 [labelimg] 사용, 라벨 이름과 설정한 영역의 위치가 저장된 [.xml] 파일이 생성

labelImg (라벨링 도구) 
- 학습
- 개발 언어 : Python
- IDE : Jupyter Notebook, PyCharm
- 관련 파라미터 설정 (Model : 수정했던 cfg 파일, Optimizer : Adam)
- Hyper parameters (batch size : 4, epoch : 총 200 (learning rate마다 다르게 설정), learning rate : 1e-4, 1e-5, 1e-6 으로 점차 줄여가며 설정)

파라미터 설정 주요 코드 
학습 진행 예 - 탐지 및 모자이크 처리
- 영상에서 하나의 frame을 추출
- frame을 학습시킨 모델에 통과시킴
- 통과시킨 frame에 탐지된 객체가 있다면,
- 해당 부분을 모자이크 처리
- 처리가 완료된 frame을 쌓아 영상으로 만듦

3. 테스트 및 시연 영상 (이미지 캡쳐)

동영상 일부 캡쳐 (칼 모자이크 예)
4. 예제 소스코드 설명
0) 설명에 앞서
- 프로젝트가 마무리된 후, 작업에 대한 파일 관리를 소홀히하여 dataset과 source code가 망가져 버렸다. (연구실 PC가 갑자기 망가져버린 이유도 있다.)
- 이번을 계기로 산출물, source code의 관리의 소중함을 다시 한 번 깨닫게 되었다.
- 아래의 설명은, 본 프로젝트에서 수행한 yolo, dataset의 버젼과 구조가 조금 다르다.
- yolo의 경우 v5는 환경 구축 및 학습 과정이 더욱 간편해져 좋았지만, dataset의 경우 프로젝트에서 맡았던 역할이었지만, 복구가 어려워 이 점이 많이 아쉽다.
1) dataset 가져오기

- roboflow에서 (임시로) dataset을 가져왔다.
- 운이 좋게도, 연구실에서 진행했던 다른 프로젝트 중, 공사 현장에서 직원들이 안전모를 썼는지 안썼는지에 대한 데이터 셋을 구축할 일이 있었는데, 이에 대한 예시 자료가 있었다. 이를 가져왔다.
2) yolo v5 clone, 관련 package 설치

- yolo v5를 clone을 통해 설치하고, 관련 library package를 함께 설치한다.
- 요구되는 package는 다음과 같다.

3) data.yaml 구조

- data.yaml은 다음을 정의하는 Dataset Configuration File(데이터셋 구성 파일)이다.
- 자동 다운로드를 위한 command 또는 URL 옵션
- training dataset의 경로
- validation dataset의 경로
- class의 개수
- class의 구성
4) glob을 활용하여, image 가져오기
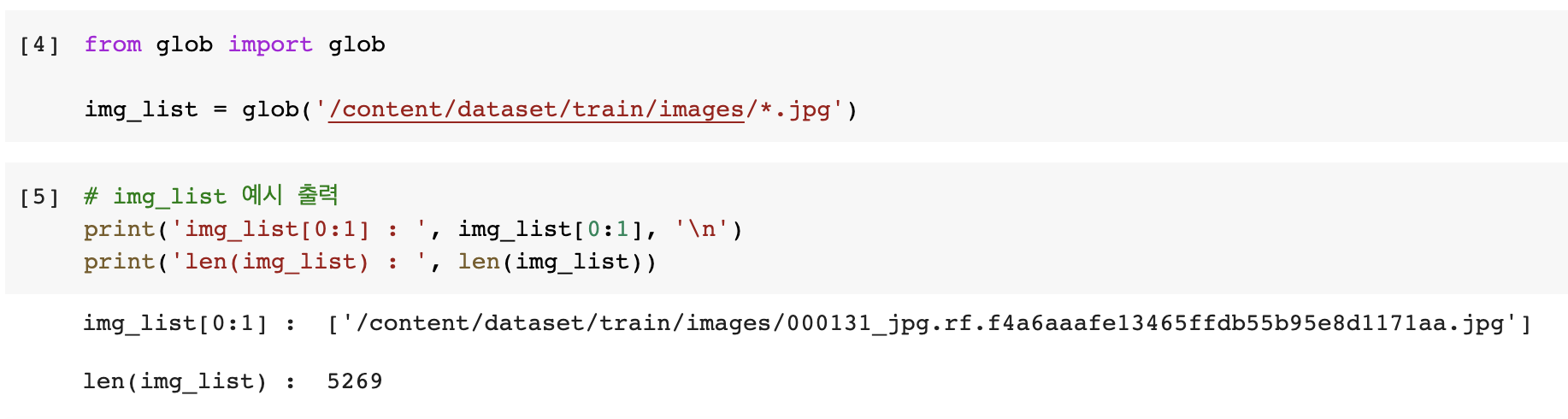
- glob : 파일을 자유롭게 다룰 수 있는 라이브러리이다. 디렉토리 내의 파일들을 list로 리턴하기 위해 사용한다.
- img_list라는 list에 파일들의 경로를 모두 저장한다.
- image의 경로 및 구성은 다음과 같다.

5) train_test_split을 활용하여, image 나누기

- 전체 image dataset을 모두 학습에 사용한다면, 제 성능을 발휘하는 모델을 만들 수 없다.
- 모델이 학습 데이터에 과하게 학습된 나머지, 조금이라도 벗어난 다른 image에 대해서는 예측하지 못하기 때문인데, 이를 overfitting되었다라고 한다.
- 때문에, 전체 image dataset을 train dataset과 validataion dataset으로 적절히 나누어야 한다.
- 이를 위해, sklearn의 train_test_split을 사용한다.

- train_test_split(test_file_name, test_size, shuffle, stratify, random_state)
- test_file_name : 분할 할 원본 리스트
- test_size : dataset의 구성 비율. 0.2라면, train dataset : valid dataset = 8 : 2로 나누어진다.
- shuffle : 분할 전 섞을지에 대한 boolean 값인데, default = True이다.
- random_state : 섞을 때 사용되는 seed value
6) txt 파일 생성

- data.yaml에서 사용될 txt파일을 생성하는 과정이다.
- with를 통해 파일을 다루면, 열고 닫는 과정이 간편하다.
- join을 통해, 문장들 앞, 뒤에 개행을 추가한다.
- txt 파일들의 내용은 다음과 같다.

7) data.yaml의 train, val 경로 수정

- data.yaml을 수정한다.
- ps) yaml파일을 python을 통해서는 처음 다뤄보는데, 그래도 elasticsearch를 조작할 때 yml 파일을 다뤘던 것과 크게 다르지 않았다.
8) 학습 시작

- img : 입력 이미지 크기
- batch : 한 번 학습할 데이터의 크기
- epochs : 반복 학습 횟수
- data : yaml 파일 경로
- cfg : 모델 설정 지정
- weight :가중치 custom 경로 지정
- name : 결과 파일 명
- 학습 완료의 모습이다.

9) 테스트 이미지를 통한 추론 과정

- validation dataset의 이미지를 가져와서, 학습한 모델에 적용해본다.
- 실행 명령어에서, "{val_img_path}'와 같이 작성할 때, python의 변수를 넘겨줄 수 있다.
10) 적용 예



- 잘 탐지가 된 것을 확인할 수 있다.
- 다양한 지표를 통해 모델의 성능을 살펴보면 다음과 같다.
 728x90
728x90'Project' 카테고리의 다른 글
[Elastic Stack] 서울시 IoT 도시 데이터 분석 및 시각화 (0) 2021.02.20 [공모전] 119 신고 도움 서비스, 119NER (1) 2020.12.07 [인턴] 실시간 화재 예측 시스템(RFMS) 효과성 측정 및 기능 고도화 ISP (0) 2020.09.25 [공모전] 마스크 미착용자 탐지 서비스, KOMO (2020포스트코로나AI챌린지) (0) 2020.05.27 [DEMO] Linux 채팅 프로그램 제작 프로젝트 (1/2) (0) 2020.05.11 -