
Process 요약
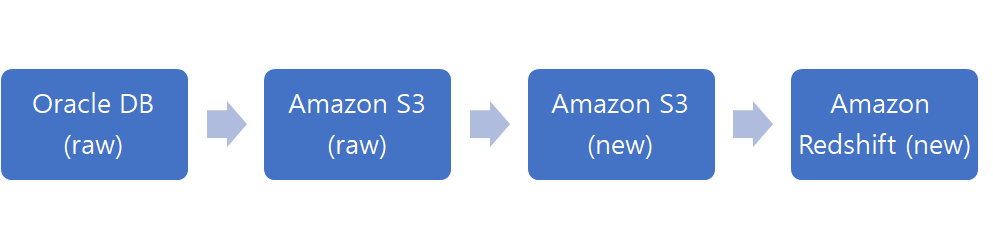
- Oracle DB에 저장된 raw 데이터를, Glue의 작업(job)을 통해 Amazon S3로 가져온다.
- 가져온 데이터를 Glue의 크롤러(crawler)를 통해 읽어 테이블로 저장한다.
- Amazon Athena를 통해 테이블을 조회하여 정합성을 따진다.
- 가져온 테이블의 데이터가 문제없다면, Glue의 새로운 작업을 통해 Amazon S3의 데이터를 Amazon Redshift로 보낸다.
1. raw 데이터 확인
- 목적 : 각 테이블의 컬럼의 의미, 타입 정의 등을 확인하고, 이관(migration) 시 어떠한 타입으로 매핑할지를 정의한다.
- 해당 테이블의 컬럼이 무슨 의미를 가지는지, 타입(type)은 무엇인지, 길이는 어떻게 되는지, NULL 값을 허용하는지 등에 대해 파악한다.
- 이 때 엑셀을 활용하면 좀 더 수월하게 체크 가능하다.
- Oracle DB의 데이터를 Source라 하고, Amazon S3에 옮겨질 데이터를 Target이라고 하며, 다음과 같이 1:1로 정의한다.
 source data 정의 예시
source data 정의 예시
 target data 정의 예시
target data 정의 예시
2. Oracle DB to Amazon S3
- AWS Glue의 작업(job)을 생성한다.
- IAM 역할, 스크립트가 저장되는 S3 경로의 설정의 체크하고, 마지막 부분의 '카탈로그 옵션'을 선택한다.
- 이 때, '이름'과 '스크립트 파일 이름'이 일치하는지 주의한다.

- Oracle DB는 Amazon VPC 기준으로 외부 환경이기 때문에, 별도의 '연결'을 설정해야 한다.
- [AWS Glue - 데이터베이스 - 연결]을 통해 Oracle DB와 S3 간 연결을 설정한다.

- spark 코드를 활용하여 Oracle DB와의 connect 코드, 쿼리 코드, 매핑 코드 등을 script에 작성한다.
- sql 쿼리 코드를 작성할 때, 'SELECT * FROM TABLE_NAME"과 같은 '*'의 사용을 지양한다.
- 아래 예시와 같이, 조회할 컬럼명을 모두 수동적으로 명시하여 예상치 못한 오류를 최소화한다.
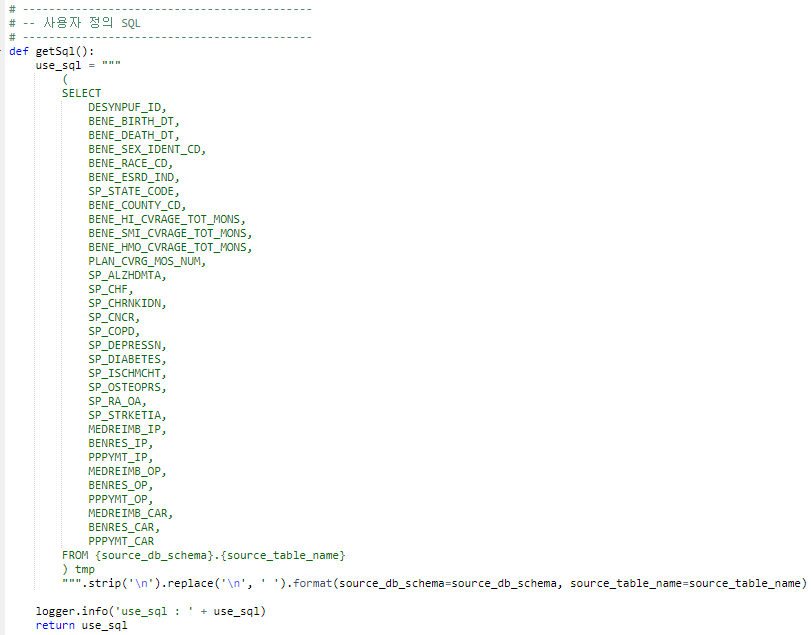 sql 쿼리 예시
sql 쿼리 예시
- 매핑 코드의 경우, (source_column_name, source_type, target_column_name, target_type)을 작성하는 것이 원칙이지만, 만약 동작하지 않는다면, (source_column_name, target_type, target_column_name, target_type)으로 작성한다.
3. Amazon S3 데이터 확인
- AWS에서 기본적으로 파케이(parquet)라는 포멧의 파일 단위를 사용한다.
- 위의 과정을 통해 파케이 타입의 데이터로 가져오게 되고 해당 파일을 읽고 조회하기 위해서는 크롤러(crawler)를 생성하여 해당 파일을 읽어야 한다. (말 그대로 크롤링해야 한다.)
- 일반적으로, 작업 1개 당 크롤러가 1개 생성된다.
- 포함 경로를 설정할 때, 읽을 파케이 파일이 포함된 경로를 선택한다.
- 이 때, 읽을 파케이 파일이 해당 경로에 여러 개가 있다면, 파일을 하나만 선택하더라도 해당 경로 내의 모든 파일을 한 번에 읽게 된다.
- 따라서, 이를 원하지 않는다면, 파케이 파일 별로 경로를 별도로 설정해두는 것이 좋다.

4. AWS Athena를 통해 데이터 조회
- 크롤러를 통해 데이터를 읽었다면, AWS Athena를 통해 해당 데이터를 조회할 수 있다.
- Athena에서 '데이터 원본'과 '데이터베이스'를 선택하고 조회 쿼리를 작성하면, 결과를 확인할 수 있다.
- Oracle DB를 조회할 수 있는 DBMS 툴에서의 쿼리와, Athena에서의 쿼리를 수행하며 raw 데이터와 이관한 데이터 간 정합성을 따진다.
- 기본적인 전체 조회를 시작으로, min(), max(), avg(), count(distinct) 등을 조회한다.
 aws athena 예시
aws athena 예시
5. Amazon S3 to Amazon S3
- 목적 : 가져온 raw 데이터를 기반으로 목적에 맞는, 요청 사항에 맞는 새로운 데이터를 생성한다. data mart를 생성하는 과정이라고도 한다.
- Oracle DB to Amazon S3 과정과 크게 다르지 않다.
- 다만, 외부로부터 데이터를 가져오는 것이 아니기 때문에 별도의 '연결' 과정이 필요없다.
- 이 과정에서도 역시, 새로운 데이터의 타입을 미리 조회하여 script의 매핑을 정의할 때 작성함을 주의한다.
- raw 데이터를 기반으로 만든 새로운 데이터 테이블을 'New table'이라고 칭하고, New table을 AWS에서 사용할 수 있도록 위와 같은 크롤링 과정을 수행한다.
- 크롤링을 통해 New table에 대한 데이터를 가져왔다면, Athena를 통해 조회하여 정합성을 따진다.
6. Amazon S3 to Amazon Redshift
- 마찬가지로 작업을 생성하여 스크립트에 관련된 코드를 작성하면 된다.
- 이 때 주의할 점은, New table에 대한 데이터를 복사(copy)하기 전에 해당 데이터가 들어갈 테이블을 먼저 생성(create)해야 한다.
- 즉, 두 개의 쿼리를 작성해야 하고, 먼저 'CREATE TABLE ~'에 대한 쿼리를 수행한 후, 'COPY FROM ~'을 통해 데이터를 복사한다.
- 첫 번째 쿼리의 수행 완료 후, 두 번째 쿼리가 수행되어야만 하고, 데이터의 크기와 네트워크 환경 등을 고려하여 두 쿼리 간 시간차가 필요하다면 이에 대한 코드도 추가 작성한다.
7. 워크플로(workflow) 만들기
- 위의 모든 과정을 '한 번'의 작업 수행을 통해 자동화하기 위해 '워크플로'를 만든다.

- 워크플로를 활용한다면, Oracle DB로부터 raw 데이터를 가져와 S3에 저장하고, 저장된 S3 데이터로부터 새로운 데이터(new table)를 만들고, 새롭게 만든 데이터를 다시 S3에 저장하여 Redshift로 가져오기까지의 과정을 한 번에 수행할 수 있다.
- 이 때 옵션 사항으로, 특정 이벤트가 발생할 때 또는 특정 일자, 일시 또는 필요할 때마다 워크플로가 동작할 수 있도록 설정할 수 있다.
- 워크플로의 경우, 한 번 작성하거나 설정한 옵션 사항에 대해서 작업 도중에 수정이 불가하다. 때문에 수정이 필요하다면 워크플로를 삭제하고 다시 만들어야하니 주의가 필요하다.
 워크플로 예시
워크플로 예시
- 기존의 생성된 S3 데이터 등을 모두 삭제하고 워크플로를 실행해보면, 몇 분 뒤 해당 작업이 모두 완료된 것을 확인할 수 있다.
8. Amazon QuickSight로 시각화하기

- Amazon에서 제공하는 분석 및 시각화 도구인 QuickSight를 이용하여 위와 같이 시각화 자료를 제작할 수 있다.